Isaac Bernat
Staff Software Engineer
Experience
Independent Professional Development
An intentional period of independent engineering, focused on shipping production-grade projects, modernizing backend workflows, and integrating privacy-first AI tooling. Key activities include:
AI Data Pipelines: Architected the basepaint archive using a production-grade custom Python orchestrator to manage resilient LLM ingestion. Features robust concurrency control with rate limiting and exponential backoff (
tenacity,asyncio) and strict data validation (pydantic) to handle stochastic AI outputs.Agentic CI/CD Engineering: Modernized the popular netflix-to-srt open-source tool (850+ GitHub Stars) via AI orchestration. This involved hosting distilled LLMs (Qwen3.5) locally in Orbstack containers to ensure a zero-data-leakage environment for generating multi-language unit tests (Python
unittest&node:test) while keeping strict zero-dependency constraints.Hardware-Constrained Polyglot: Engineered a unique 50 FPS real-time asymmetric multiplayer game in Lua for the Playdate console. Designed a custom particle system with object pooling (300+ independently moving particles with zero Garbage Collector churn). Officially selected for publication in the curated Playdate console Catalog.
System Design: Authored a comprehensive, production-level technical design for a heuristic-based Spam Classification Engine, a pragmatic approach to building resilient features within legacy ecosystems.
A curated selection of GitHub Projects from this period is detailed below.
Preply
Staff Backend Engineer
Jun 2022 – Jul 2024
As a Staff Engineer, I operated beyond my immediate team to shape the technical roadmap and lead complex, cross-functional initiatives. My role was to tackle the most ambiguous business problems, translate them into robust backend architectures, and drive them to completion.
Architectural Leadership & Monetization: Led the company's #1 most impactful A/B test of 2023, driving a +3% global Gross Margin lift. Redesigned the core subscription monetization logic, engineering an idempotent, cron-driven state machine with strict database-level locking to guarantee zero double-billing during asynchronous payment gateway failures. (Read the Full Case Study)
Proactive System Observability: Consistently identified and mitigated critical production bottlenecks outside my team's direct domain. Engineered a pragmatic rate-limiting circuit breaker to neutralize an automated transaction-fee arbitrage exploit, and traced/mitigated a runaway Celery task executing >1M times/hour.
Engineering Velocity & Cost Optimization: Championed an engineering-wide CI/CD optimization initiative. Identified a severe Jenkins queue bottleneck and drove an on-demand testing workflow for Draft PRs, reducing automated-test AWS EC2 infrastructure costs by 80% ($31k/year) and saving hundreds of collective engineering hours per month in the process. (Read the Full Case Study)
Strategic Foresight & Technical Translation: Acted as the technical DRI for cross-functional initiatives. Advocated against a high-risk monolithic launch strategy ("Subs Direct"), ultimately guiding a cross-functional pivot to an iterative release model, saving an estimated 6 months of engineering effort.
Senior Backend Engineer
Mar 2020 – Jun 2022
Founding the Subscription Platform: Served as the founding backend architect for the Subscription MVP. Designed the core schema and orchestrated cross-team integrations (Payments, CRM, Finance) that scaled to 200k+ monthly renewals. This foundation increased LTV-to-CAC from 1.4x to 3.0x and enabled a Series C funding round. (Read the Full Case Study)
Incident Leadership & Observability: Commanded and documented 15+ production incidents. Leveraged a critical SEV-2 post-mortem to champion a mandatory, company-wide pre-launch observability policy, shifting the engineering culture towards monitoring-first deployments. (Read the Incident Retrospective)
Team Scaling & Process Improvement: Played a key role in scaling the dedicated Subscriptions team by interviewing 13 candidates and hiring 2 of its foundational engineers. I also redesigned our sprint retrospective process, which cut meeting time by 50% while increasing actionable outcomes and team engagement.
Modernization & Database Performance: Led the backend migration of the high-traffic (1M+ MAU) Q&A application from legacy Django templates to a GraphQL API. Resolved database query bottlenecks to reduce page load time by >85%, unblocking experiments that drove a +300% lift in New Paying Customers.
Ivbar Institute
Fullstack Engineer
Jan 2019 – Mar 2020
Stepped into a fullstack role to meet team needs, contributing to both a Python backend and a React-based frontend for visualizing complex healthcare data.
Technical Expertise & Communication: Selected to speak at PyCon Sweden 2019. Presented a deep-dive on bytecode-level and algorithmic optimization, demonstrating how to reduce O(n^3) bottlenecks to O(1) through memoization, search-space reduction, CPython profilers and other techniques.
Data Visualization: Engineered a React-based UI to display complex medical case-mix decision trees, empowering healthcare professionals to better understand and analyze treatment pathways.
Backend Engineer
Mar 2018 – Jan 2019
Developed privacy-first data processing systems focused on data integrity and the secure handling of sensitive patient information.
Healthcare Analytics: Architected the core data processing engine for the Swedish National Quality Registry for Breast Cancer (NKBC), a system enabling nationwide analysis of treatment outcomes across different hospitals to identify and share best practices.
Data Privacy & Security: Implemented MECE-compliant privacy filters to ensure patient k-anonymity in highly sensitive medical datasets. This feature was designed with the explicit constraint of operating within secure, on-premises hospital environments, a critical requirement for meeting strict data governance and ethical standards.
Productos Aditivos
Technical Operations Lead
Led the technical modernization of core enterprise operations, driving data intelligence and managing critical infrastructure vendor relationships.
Data-Driven Business Intelligence: Engineered a custom market intelligence data pipeline, aggregating and analyzing international customs data to deliver strategic supply-chain forecasting on competitor/supplier volumes and pricing during global macroeconomic events (e.g., the months-long factory shutdowns during China's "Central Environmental Protection Inspection (CEPI)").
Technology & Vendor Management: Managed the technical vendor relationship for a highly constrained legacy ERP system. Oversaw the mandatory company-wide transition to the Spanish SII real-time tax reporting API system, ensuring business continuity and regulatory compliance.
Wrapp
Progressed from an early, versatile engineer to a key Tech Lead during the company's critical "Wrapp 2.0" pivot, transforming the architecture from a legacy monolith to modern microservices. I was also selected to speak at the inaugural PyCon Sweden.
Tech Lead
Sep 2014 – Jun 2016
Microservice Architecture: Helped guide the pivot from a Python 2.7/Twisted monolith to a distributed system of 50+ microservices in Go and Python 3.
Core Service Ownership: Maintained critical backend services:
users(Python) andoffers(Go). I was responsible for their architectural consistency and code quality. For coreoffersservice this meant overseeing 1,200+ commits from over 12 contributors.Fintech Backend: Built the core backend APIs for mapping credit card transactions to merchant offers, contributing to "Wrappmin" merchant dashboard.
Developer Tooling: Designed and built "Opsweb", a mission-critical internal deployment system for managing canary releases. It directly improved developer velocity and site reliability with features like automated health checks and rollbacks.
Early Engineer (Backend, Data, Frontend)
Oct 2012 – Sep 2014
Fraud Prevention: Created a heuristic-based fraud prevention system to detect and block abuse of the platform’s gift card and coupon features, protecting the company and its customers from financial loss.
Data Engineering & Visualization: Architected and optimized the high-volume ETL pipeline for our Redshift data warehouse and built real-time KPI dashboards for business and system monitoring.
Complex Frontend Engineering: Evolved a comprehensive A/B testing email framework that delivered over 1M personalized newsletters weekly. This involved complex rendering optimizations and extensive cross-client compatibility testing to ensure a consistent user experience.
Remote Collaboration: Contributed effectively in an asynchronous, multi-time-zone environment with engineering teams in both Stockholm and San Francisco.
FXStreet
Contributed to a high-traffic, multi-language financial news portal on a Microsoft Azure and C#/.NET stack, serving a global user base of forex traders.
Internationalization (i18n): Handled complex front-end challenges related to localization, ensuring UI/UX consistency across 17 languages, including right-to-left scripts (Arabic) and character sets with different spacing requirements (Russian, Japanese).
Platform Development: Maintained and developed features on the core C#/.NET platform, working within a Mercurial (Hg) version control system.
Case Studies
Model MVP: Building a Company-Defining Success (2021)
Led the backend architecture for a company-defining project that transitioned a manual, package-based business to a recurring subscription model. Architected an idempotent, cron-driven billing state machine that securely processed 200k+ monthly renewals. The solution resulted in a +41% YoY increase in LTV, an improvement on the LTV-to-CAC ratio from 1.4x to 3.0x, and was instrumental in securing a Series C funding round.
Read the full case study ↓
The Challenge: Unpredictable Revenue and High User Friction
The company's business model was based on selling prepaid packages of hours (6, 12, or 20). This created two major problems:
- For the Business: It led to unpredictable, lumpy revenue streams, making financial forecasting difficult.
- For the User: The manual renewal process created significant friction. Students would often run out of hours unexpectedly, disrupting their learning cadence.
Our proposal, "Subscribe to a Tutor", aimed to solve this by introducing auto-renewing subscriptions, based on the hypothesis that predictable lessons would align user goals with a more stable, recurring revenue foundation for the business.
Defining Success: An MVP-First, Data-Driven Approach
Because this was a fundamental change to the financial model, our strategy was not to build a fully-featured system, but to launch a Minimum Viable Product (MVP) within a controlled A/B test.
We defined success criteria for two distinct phases:
- Short-Term (MVP Launch): The immediate goal was successful validation. This required achieving statistical significance in user adoption, ensuring technical stability and generating the clean data needed to inform our decision to scale.
- Long-Term (Post-Scale): Success would be measured by a sustainable increase in key business metrics, including User Retention, Customer Lifetime Value (LTV) and Gross Merchandise Value (GMV).
The Solution: Pragmatic Scoping and Product Decisions
My approach was centered on one goal: speed-to-learning. This involved several critical product and delivery decisions that I championed.
1. Strategic Billing Cycle
I advocated for a 4-week billing cycle over a standard monthly one. This was a crucial, non-obvious decision with multiple benefits:
- User Alignment: It perfectly matched the weekly lesson cadence of our students.
- Predictability: It created fixed-size packages every single time.
- Business Velocity: It provided the business with customer insights ~8% faster and resulted in 13 billing cycles per year instead of 12, compounding revenue.
We anticipated a small increase in customer support queries from users accustomed to monthly billing, but we judged the significant benefits to be a worthwhile trade-off, which proved to be correct.
2. Aggressive MVP Feature Scoping
We deferred all non-essential features. For example, we launched without dedicated "upgrade/downgrade" functionality, knowing that users could achieve the same outcome through the existing workflow of canceling and re-subscribing. This kept the initial build lean and focused.
3. Strategic Plan Sizing
We limited the MVP to three distinct plans (1, 2, or 4 weekly hours). This was a deliberate choice to ensure direct comparability with the three tiers of the existing package model, eliminating "decision fatigue" or plan size as a confounding variable in our A/B test results.
4. A Carefully Restricted Audience
To accelerate delivery and minimize the "blast radius" of any potential issues, we launched to a very specific audience segment:
- New users only (without referrals): To avoid bias from prior experience with the package model.
- English-UI users only: To simplify the initial copy, design work and avoid localization overhead.
- Web-only users: To bypass the slower, more complex release cycles of our mobile applications.
- Single Payment Provider (Braintree): To avoid the significant effort of building recurring payment support for other (marginal) providers like Stripe or PayPal at the MVP stage.
Delivery & Iteration: Parallel Cohorts
Our most significant time-saving decision was to launch with a partial backend implementation. We went live with the user-facing sign-up flow while the auto-renewal logic and emails were still being built, allowing us to gather behavioral data weeks earlier.
This rapid approach enabled a sophisticated testing strategy. Instead of a single A/B test, we launched several experimental cohorts in parallel, each with an incrementally richer feature set (e.g. adding plan upgrades, more plan sizes). This had never been done before at the company and it provided the rich, long-term data needed to confidently scale the full subscription model.
Deep Dive: The Critical Architectural Decision
When dealing with recurring payments, 100% idempotency and correctness are vastly more important than millisecond latency. A single race condition resulting in double-billing destroys user trust and creates massive financial liability.
Instead of over-engineering a complex event-driven "Saga" pattern, I evaluated the trade-offs and architected a highly resilient, idempotent cron-driven state machine implemented as a logically isolated module within our legacy Python/Django monolith.
To de-risk the execution and guarantee financial data integrity at scale, I engineered several core safeguards:
Strict Database-Level Locking: The most significant technical risk was race conditions occurring between our scheduled hourly renewal cron jobs and asynchronous payment webhooks (Braintree). I implemented strict row-level database locking during state transitions. This guaranteed that even if a network timeout occurred, a worker crashed, or a webhook fired simultaneously, a user could never be double-charged.
Idempotent State Schema & Custom Cohort Tracking: I designed the dedicated subscription tables with strict state constraints (e.g. tracking
next_charge_time). Because our internal A/B testing platform couldn't handle overlapping, multi-cycle long-term experiments, I engineered a customexperiment_cohortschema. This allowed the billing engine to run multiple parallel feature permutations safely, with clear historical financial data traceability and without corrupting active subscriptions.Blast-Radius Isolation: All new billing code was built in a strictly bounded context with its own database tables, preventing performance degradation for non-subscribers. Furthermore, all entry points were guarded by a centralized "kill switch" feature flag, allowing us to instantly halt the renewal engine without requiring a rollback deployment if an anomaly was detected.
This pragmatic, highly resilient architecture proved its worth. It allowed rapid validation and was easily scaled to process over 200k automated renewals per month with near-zero maintenance overhead. It provided a solid foundation to seamlessly add complex features like plan upgrades/downgrades, top-ups, pauses, variable billing cycles, and breakage policies in future iterations.
The Results: A Company-Defining Success
The project became the most impactful experiment in the company's history. Within four months of scaling the model to all new users, we achieved:
- A +41% year-over-year increase in LTV directly attributable to the project.
- An LTV-to-CAC ratio that improved from 1.4x to 3.0x.
- The successful close of a Series C investment round, larger than all previous rounds combined.
Within a year, the subscription model accounted for 64.4% of the company's total lesson revenue, fundamentally transforming its financial foundation.
Key Personal Learnings
- Observability is a Feature, Not an Afterthought: We initially deprioritized building robust monitoring due to deadline pressure. This decision directly led to a SEV-2 incident that went undetected for 16 hours. I now consider comprehensive monitoring and alerting to be a non-negotiable part of the initial delivery of any critical system.
- Lead with a Proposal, Not just Options: As the Directly Responsible Individual (DRI), I learned my role wasn't just to analyze trade-offs, but to lead with an assertive, well-reasoned recommendation. Embracing this mindset accelerated key architectural decisions.
- The Power of Pragmatism (YAGNI): This project succeeded because we kept the MVP minimal. A later, failed attempt to launch "yearly subscriptions" was over-engineered for future flexibility that we never needed. It was a powerful lesson in the "You Ain't Gonna Need It" principle. I now challenge complexity much more forcefully, always advocating for the simplest solution that can validate the core hypothesis. (Read the full retrospective on that project).
Subscription Optimization: A Crisis Turned into Best Experiment (2023)
As the epic lead and sole backend architect, I drove a company-wide initiative to overhaul our subscription lifecycle policies. By engineering a pragmatic, state-based billing deferral system, making a critical, data-informed decision to trust long-term retention over short-term noise and pushing back against brittle product requirements, this project was turned into the most impactful experiment out of all 215 A/B tests in 2023, delivering a +3% global Gross Margin lift.
Read the full case study ↓
The Challenge: A "Leaky Bucket" in Our Subscription Model
Our subscription model had a "pause" feature, but it was a blunt instrument. When users paused, they were completely locked out of taking lessons and any lessons they had scheduled were automatically canceled. This created significant user friction.
Data revealed a critical problem: users were canceling their subscriptions at twice the rate they were using the pause feature. They were opting for the more drastic "cancel" option simply to gain flexibility, creating a "leaky bucket" that drove high churn. Our hypothesis was that by offering a more user-friendly alternative to pausing and by aligning our cancellation policy with industry standards, we could improve both user retention and key financial metrics.
Uncovering a Hidden Liability
Digging deeper, I found that our existing system had a significant flaw: when users canceled, their prepaid hours remained on their balance indefinitely. This was not a deliberate product decision but an implementation artifact from the initial MVP. It created a growing, multi-million dollar liability on our books, as this money technically still belonged to the users. My proposal to expire hours on cancellation was not just about aligning with industry standards, it also was about resolving this hidden financial risk.
My Role: Epic Lead and Backend Architect
As the epic lead for this company-wide initiative, I was responsible for more than just the code. My role involved:
- Coordinating a cross-functional effort of 15+ people from various teams, including Backend, Frontend, Product, CRM and Financial Data, each with their own different goals and priorities.
- Championing the core product strategy, which I had advocated for across three consecutive quarters.
- Architecting and personally implementing 100% of the backend logic.
- Driving an accelerated delivery timeline by proactively de-risking the project.
The Solution: A Two-Part Strategy
We proposed a bold, two-part solution to be tested in a single A/B experiment:
- A More Flexible "Postpone" Feature: We replaced the rigid "pause" with a new "Change Renewal Date" feature. This allowed users to postpone their next billing date by up to 20 days, once per cycle, without losing access to their lessons or having their scheduled classes canceled.
- A Policy to Expire Hours on Cancellation: To create a clearer distinction and align with standard subscription practices, we implemented a policy where any unused hours would expire at the end of the billing cycle upon cancellation.
To accelerate the launch, I identified the critical path, which was blocked not just by technical tasks but by dependencies on our CRM, Financial Data and Frontend teams. I personally championed the project with these teams, negotiating to get our dependencies prioritized even when they fell outside their quarterly goals. This cross-functional leadership, combined with developing key backend components in parallel with ongoing user research, was instrumental in launching the full experiment four weeks ahead of our official schedule (2 sprints).
Ensuring a Scientifically Valid Test
A crucial part of the experiment design, which I insisted upon, was to ensure the integrity of our results. A significant portion of the "unexpired hours" liability came from users who had canceled months or even years prior. Including the one-time financial gain from expiring these historical hours in the A/B test would have massively inflated our short-term metrics and given us a misleading, irreproducible result. Therefore, I designed the backend logic to only apply the new expiration policy to users who canceled after the experiment start date, ensuring we were measuring the sustainable, long-term impact of the change.
Technical Deep Dive: The Pragmatism of KISS
While the business logic seemed straightforward, safely mutating the state of active subscriptions required extreme pragmatism to avoid runaway architectural complexity. I focused on three core engineering decisions:
Preventing "Cycle Drift" (Pushing Back on Product): Product initially requested that postponed billing dates be calculated exactly 28 days from the previously scheduled charge. I actively pushed back. In a real-world billing engine, payment retries (dunning) often take hours or days to succeed. If we anchored to the theoretical date, every retry delay would permanently shrink the user's next cycle. I architected the system to anchor the new 28-day cycle to the actual successful charge timestamp, preventing cycle drift and proactively eliminating a massive wave of future Customer Support tickets.
The "Grace Period" Architecture (Business Logic > Async Complexity): To mitigate user frustration upon cancellation, we needed a 48-to-72 hour grace period before permanently expiring hours. A junior approach would involve building a complex, asynchronous "temporary deletion" state machine. Instead, I leaned into KISS (Keep It Simple, Stupid). Knowing that our Finance team ran their massive ETL reporting jobs days into the new month, I opted to hard-expire the hours immediately in the database, but built a targeted REST endpoint for Customer Support. If a user complained within the window, CS could click a button to instantly restore the hours. We achieved the exact same business goal with zero asynchronous complexity or background worker risks.
Enforcing Rules via Lean State: We needed to restrict users to one postponement per cycle. Instead of creating new relational tables or complex locking, I simply evaluated the existing
last_postponedtimestamp against thelast_chargedtimestamp. Iflast_postponed > last_charged, the request was rejected. It was lightweight, infinitely scalable, and bulletproof.
Product Deep Dive: The "Freeze" Decision
Three weeks into the A/B test, the results looked disastrous. The data showed a significant drop in immediate Gross Margin (GMV) and there was immense pressure from stakeholders to kill the experiment.
I dug into the data and formulated a strong counter-hypothesis: the metrics were negative because the feature was working. Users were postponing payments, which naturally created a short-term dip in cash flow. The crucial missing piece of data was the long-term impact on retention. Based on early engagement signals showing "postpone" users were far more active than "pause" users, I made the high-stakes call not to kill the experiment, but to "freeze" it. This stopped new users from entering, but allowed us to track the existing cohorts over a longer time horizon.
The Results: The Most Impactful Experiment of the Year
My hypothesis was proven correct. The long-term data showed a dramatic turnaround. The project was scaled and became the single most impactful initiative of 2023, out of 215 A/B tests (161 superiority and 54 non-inferiority experiments) launched company-wide.
- Financial Impact: It delivered a +34% Gross Margin increase within the experiment group, contributing to a +3% global GM lift for the entire company.
- Retention Impact: It drove a +4.4% increase in the subscription renewal rate and a +15% increase in plan upgrades.
- User Trust: To mitigate the risk of the new policy feeling unfair, I worked with the CRM team to implement clear, proactive email warnings and built a 24-hour "grace period" into the backend logic to give Customer Support a window to easily reverse accidental cancellations. As a result, we saw no significant spike in user complaints related to the new policy.
This project became a new model for the company on how to analyze complex, long-term experiments and reinforced the value of making data-informed decisions, even when the initial signals are noisy and negative.
A Failed Experiment: Key Lessons from Yearly Subscriptions
A retrospective on a failed experiment to launch yearly subscriptions. This project became a powerful lesson in the importance of upfront product validation and the engineering principle of YAGNI ("You Ain't Gonna Need It"), leading to a more pragmatic and data-driven approach in subsequent work.
Read the full retrospective ↓
The Challenge: The "Obvious" Next Step
Following the immense success of our initial 4-week subscription model, the next logical step seemed to be launching a yearly subscription option. The hypothesis had several layers: we could increase long-term user commitment, create a more predictable annual revenue stream and further reduce churn by offering a compelling discount for a year-long commitment.
While we had qualitative data from user research teams suggesting this was a desired feature, the team, myself included, moved into the implementation phase with a high degree of optimism, without fully scrutinizing the underlying business and logistical assumptions.
The Technical Approach: A Mistake in Foresight
Anticipating that the business would eventually want other billing periods (e.g. quarterly for academic terms or summer programs), I made a critical technical error: I over-engineered the solution.
Instead of building a simple extension to support period=yearly, I designed a highly flexible system capable of handling any arbitrary billing duration. This added significant complexity to the codebase, testing and deployment process. My intention was to be proactive and save future development time, but it was a classic case of premature optimization.
The Outcome: A Failed Experiment and Valuable Lessons
We launched the A/B test, but the results were clear and disappointing: the adoption rate for the yearly plan was negligible. The discount we could realistically offer, after accounting for tutor payouts and our own margins, was simply not compelling enough for users to make a year-long financial commitment.
The feature was quickly shelved. The complex, flexible backend system I had built became dead code. This failure was a powerful learning experience that fundamentally improved my approach as an engineer and technical lead.
Learning 1: Validate the Business Case Before Building
The project's failure could have been predicted and avoided with a more rigorous pre-mortem and discovery phase. We jumped into building without asking the hard questions first.
- Tutor Viability: The entire premise rested on offering a discount. We never validated if enough tutors were willing to absorb a significant portion of that discount. The handful who agreed to the pilot did so only after heavy negotiation, with the company subsidizing most of the cost, a model that was completely unscalable.
- Logistical Complexity: We hadn't solved the critical operational questions. What happens if a student's tutor leaves the platform six months into a yearly plan? The processes for refunds, tutor reassignment and the accounting implications were undefined, creating massive downstream risk for our Customer Support and Finance teams.
- Relying on Overly Optimistic Data: I learned to be more critical of qualitative user research that isn't backed by a solid business case. I took the initial presentations at face value, without questioning the difficult financial and operational realities.
This taught me to insist on a clear, data-backed validation of the entire value chain, not just user desire, before committing engineering resources.
Learning 2: The True Meaning of YAGNI
My attempt to build a "future-proof" system was a direct violation of the "You Ain't Gonna Need It" principle. The extra effort and complexity I added not only went unused but also made the initial build slower and riskier. This experience gave me a deep, practical appreciation for building the absolute simplest thing that can test a hypothesis. It's not about being lazy; it's about being efficient and focusing all engineering effort on delivering immediate, measurable value.
This project, more than any success, shaped my pragmatic engineering philosophy and my focus on rigorous, upfront validation.
CI/CD Optimization: Driving $31k in Annual Savings with a 1-Day Fix
Identified a key inefficiency in our CI/CD pipeline and led a data-driven initiative to fix it. This simple change, implemented in one day, resulted in an 80% reduction in unnecessary test runs, saving over $31,000 USD annually in infrastructure costs and hundreds of hours in developer wait time.
Read the full retrospective ↓
The Challenge: An Inefficient and Expensive CI Pipeline
In a May 2022 engineering all-hands meeting, a presentation on our infrastructure costs revealed a surprising fact: 18% of our entire AWS EC2 spend was dedicated to CI/CD. This sparked an idea. Our process ran a comprehensive, 15-minute unit test suite on every single commit, including those in Draft Pull Requests.
This created two clear problems:
- Financial Waste: We were spending thousands of dollars every month running tests on code that developers knew was not yet ready for review.
- Developer Friction: The Jenkins queue was frequently congested with these unnecessary test runs, increasing wait times for developers who actually needed to merge critical changes.
My Role: From Idea to Impact
As the originator of the idea, my role was to validate the problem, build consensus for a solution and coordinate its rapid implementation.
The Solution: A Data-Driven, Consensus-First Approach
My hypothesis was that developers rarely need the full CI suite on draft PRs, as they typically run a faster, local subset of tests. A simple change to make the CI run on-demand would have a huge impact with minimal disruption.
My approach was fast and transparent:
- The Proposal: I framed the solution in a simple poll in our main developer Slack channel. The message was clear: "POLL: wdyt about only running tests on demand for Draft PRs? ... This could help reduce [our AWS costs]. ... We could type
/testinstead." I also credited the engineer who had already prototyped an implementation, building on existing team momentum. - Building Consensus: The response was immediate and overwhelmingly positive. Within a day, the poll stood at 20 in favor and only 2 against. With this clear mandate, we moved forward.
- Rapid, Collaborative Implementation: I coordinated with the engineer from the Infrastructure team who had built the prototype. We ensured the new workflow was non-disruptive: developers could still get a full test run anytime by typing the
/testcommand. We had the change fully implemented and ready for review the same day.
The Results: Immediate and Measurable Savings
The impact of this simple change, validated by data after three months of operation, was significant:
- Drastic Reduction in Waste: We saw an 80% reduction in test runs on draft PRs (3,990 PRs without a command vs. 1,060 with one).
- Verified Financial Savings: With a calculated cost of $1.95 per test run, this translated to immediate savings of over $2,600 USD per month, or an annualized saving of over $31,000 USD.
- Improved Developer Productivity: The Jenkins queue became significantly less congested, saving hundreds of collective engineering hours per month that were previously lost to waiting. This directly translated to faster feedback loops and a more agile development cycle.
This project was a powerful demonstration of how a single, data-backed idea, when socialized effectively, can be implemented rapidly to deliver a massive, measurable return on investment by removing friction and eliminating waste.
Incident Command: Turning a Personal Mistake into Systemic Improvements
A retrospective on a SEV-2 incident where I took full ownership of a pre-launch misconfiguration for a critical MVP. This case study details the methodical response process and the key systemic improvements that resulted, turning a personal mistake into a valuable lesson for the entire engineering organization on the non-negotiable importance of observability.
Read the full retrospective ↓
The Challenge: A Pre-Launch SEV-2 Incident (Feb 2021)
Days before the planned launch of the company-defining Subscriptions MVP, we needed to conduct final Quality Assurance on our CRM email flows. This testing had to be done in the production environment to validate the integration with our email provider.
Due to a critical misunderstanding of our internal A/B testing framework's UI, I incorrectly configured the experiment. I believed I was targeting a small whitelist of test users, but I had inadvertently set the experiment live for 100% of eligible users.
The immediate impact was that thousands of customers were exposed to an incomplete, unlaunched feature. The partial experience consisted of incorrect copy promising auto-renewal and a different set of purchase plan sizes.
My Role: Incident Owner and Scribe
As the owner of the feature and the person who made the mistake, I took immediate and full responsibility. My role during the incident was twofold:
- As the Incident Owner, I was responsible for coordinating the response, assessing the impact and driving the technical resolution.
- As the designated Scribe, I was responsible for maintaining a clear, timestamped log of all actions and communications, ensuring we would have a precise record for the post-mortem.
The Response: A Methodical Approach Under Pressure
The incident went undetected for 16 hours overnight simply because we had no specific monitoring in place for this new flow. Once it was flagged the next morning, my response followed a clear hierarchy:
Immediate Mitigation: The first action was to stop the user impact. I immediately disabled the experiment in our admin tool, which instantly reverted the experience to normal for all users and stopped the "bleeding."
Diagnosing the Blast Radius: With the immediate crisis averted, I began the diagnosis myself. I queried our database's
SubscriptionExperimenttable and quickly identified that ~250 users had been incorrectly enrolled, far more than the handful of test accounts we expected.Resolution and Cleanup: I wrote and deployed a data migration script to correct the state for all affected accounts. This ensured that no user would be incorrectly billed or enrolled in a subscription and that our A/B test data for the upcoming launch would be clean.
The incident was fully resolved in under an hour from the time it was formally declared.
The Outcome: Systemic Improvement from a Personal Mistake
While we successfully corrected the immediate issue, the true value of this incident came from the blameless post-mortem process that I led. The 16-hour detection delay became the central exhibit for a crucial change in our engineering culture.
The post-mortem produced several critical, long-lasting improvements:
- Improved Tooling: We filed and prioritized tickets to add clearer copy, UX warnings and a "confirmation" step to our internal experimentation framework to prevent this specific type of misconfiguration from ever happening again.
- A New Engineering Rule: We established a new, mandatory process: any high-risk feature being tested in the production environment must have a dedicated monitoring dashboard built and active before the test begins.
- A Foundational Personal Learning: I had personally made the trade-off to deprioritize the monitoring and observability tickets for the MVP to meet a tight deadline. This incident was a powerful, firsthand lesson that observability is not a "nice-to-have" feature; it is a core, non-negotiable requirement for any critical system. This principle has fundamentally shaped how I approach every project I've led since.
This incident, born from a personal mistake, became a catalyst for improving our tools, our processes and my own engineering philosophy.
Proactive Ownership: A UX Fix for a +27% GMV Lift
Identified a simple user experience mismatch on our mobile homepage, proactively proposed a low-effort A/B test to a different team and drove a +27% increase in Gross Merchandise Value (GMV) from the affected user segment. This case study is a testament to the power of looking beyond assigned tasks and thinking like an owner of the entire product.
Read the full retrospective ↓
The Challenge: A Simple Observation, A Big Opportunity
While working on a backend task, I was reviewing our platform's user flow and made a simple observation. Our homepage used the same 'hero image' for all users: a person on a laptop. While this was perfectly appropriate for desktop visitors, it struck me as a subtle but significant disconnect for a user visiting our site on their phone. My hypothesis was that this 'one-size-fits-all' approach was creating a subconscious barrier, making the product feel less relevant to mobile users and potentially harming conversion.
My Role: Proactive Contributor
This was a clear example of an opportunity that fell outside my direct responsibilities and team's domain. My role was not to implement a fix, but to act as a proactive owner of the overall product experience. This meant validating my observation with data and building a compelling, low-friction proposal for the team that actually owned the homepage.
The Solution: A Data-Backed, Easy-to-Say-Yes-To Proposal
I knew that simply flagging the issue in a Slack channel would likely result in it being lost in the backlog. To drive action, I followed a three-step process:
- Validate with Data: I partnered with a data analyst to confirm my hunch. We reviewed engagement metrics and confirmed that our mobile user segment indeed had a lower conversion rate compared to desktop users.
- Formulate a Hypothesis: I framed my observation as a clear, testable hypothesis: "Showing a mobile-centric image to mobile users will create better resonance, leading to increased engagement and conversion."
- Create a Low-Effort Proposal: I wrote a brief, one-page document for the relevant Product Manager. I didn't ask them to commit to a major roadmap change; I simply proposed a low-effort, high-potential A/B test. By doing the initial data validation and presenting a clear hypothesis, I made it as easy as possible for them to say "yes" and add it to their next sprint.
The Results: Outsized Impact from a Small Change
The homepage team was receptive and ran the A/B test. The results were immediate and exceeded all expectations. The mobile user cohort that saw a new, mobile-centric hero image demonstrated a massive improvement in key metrics:
- +27% increase in Gross Merchandise Value (GMV)
- +20% increase in total hours purchased
This initiative was a powerful lesson in the value of thinking like an owner. It proved that sometimes the most significant product improvements don't come from complex, multi-month engineering epics, but from a simple, user-centric observation and the initiative to see it through. It reinforced my belief that every member of a team has the ability to drive impact if they are empowered to look beyond their next ticket.
Strategic Alignment: A Lesson in "Disagree & Commit"
Identified a growing, underserved user segment (Music learners) experiencing significant friction due to product limitations. This case study details a data-backed advocacy effort to improve their experience, ultimately serving as a lesson in aligning individual insights with broader company strategy and the principle of "disagree and commit."
Read the full retrospective ↓
The Challenge: Overlooking Valuable Niche User Segments
Our platform's primary focus was language learning. However, I observed a significant and growing user base for other subjects, particularly Music. While these were not core growth areas, they consistently ranked in our top 10 most popular subjects by hours purchased. These subjects also had higher than average hourly rates, and represented substantial profitable revenue streams.
My concern was that these users faced unnecessary friction due to product limitations. For example:
- Lack of Specialization Filters: Unlike languages (e.g. "Business English"), Music users couldn't search for "Guitar Tutor" or "Piano Tutor", forcing them to manually scroll through long lists and click into profiles.
- Inflexible Subscription Frequencies: Many adult music learners preferred bi-weekly lessons due to practice time, but our subscription plans only offered weekly frequencies, pushing them towards less convenient options or even churn.
My hypothesis was that these overlooked user experience gaps were leading to unnecessary churn and hindering growth within these valuable niche segments.
My Role: Data-Driven Advocate
This initiative fell outside my direct team's roadmap. My role was to act as a data-driven advocate for these users, identifying the problem, quantifying the opportunity and proposing simple solutions to improve their experience.
The Solution: Building a Case for Niche Improvements
I approached this by building a clear, data-backed case:
- Quantify the Opportunity: I gathered data on the total hours and GMV generated by Music subject, demonstrating their substantial contribution to the company's bottom line, despite not being a primary growth focus.
- Highlight User Friction: I presented specific examples of user experience issues, backed by anecdotal feedback from customer support, illustrating how our generic platform was failing these specific users.
- Propose Low-Effort Solutions: I outlined simple backend changes (e.g. adding instrument specializations, allowing bi-weekly frequency options for specific subjects) that I believed could deliver high ROI by reducing friction and improving retention in these segments.
I presented this proposal to product leadership, emphasizing the potential for "easy wins" by serving an existing, valuable user base better.
The Outcome: Strategic Alignment and "Disagree and Commit"
While the product leadership acknowledged the validity of my insights and the value of these user segments, they made a strategic decision to maintain laser-focus on core language growth. Resources were explicitly allocated away from non-core subjects to maximize impact in the primary business area.
The proposed features were not prioritized in the roadmap.
This project, while not resulting in a shipped feature, provided me with a crucial lesson in "disagree and commit." I learned that:
- Advocacy is Essential, but Strategy is King: It's vital to advocate fiercely for what you believe is right, especially when backed by data.
- Respect Broader Strategic Alignment: Once a strategic decision is made, even if you disagree with it, it's essential to understand the rationale and align your efforts with the broader company goals.
- Professional Conduct: I documented my research and proposal in our internal knowledge base, ensuring the insights were preserved for future consideration. I then refocused my full energy on the prioritized roadmap items.
This experience reinforced the importance of strategic clarity and demonstrated my ability to contribute insights, influence discussions and ultimately commit professionally to the agreed-upon direction.
System Design
Spam Classification Engine
A 9-page, production-grade Technical Design Document (TDD) for a proof-of-concept spam classifier integrated into a legacy Perl ecosystem. This spec showcases a pragmatic, "white-box" heuristic architecture chosen for its interpretability, maintainability and safe phased evolution toward a modern ML service. It demonstrates deep architectural thinking, constraint management and realistic system evolution.
Download Design Doc (PDF) →Read the full document online ↓
Introduction: A Pragmatic Design for a Real-World Scenario
Designing a system to accurately identify web spam is a classic backend challenge. This document presents a technical design for a proof-of-concept (PoC) spam classifier. The goal was to solve a common, real-world engineering problem: how to build a new, critical feature within the constraints of an established, legacy ecosystem.
To simulate this scenario, the design was developed under a specific set of constraints that heavily influenced the architectural decisions:
- A Legacy Tech Stack: The design assumes the target environment is a large, mature Perl monolith. This forces a focus on integration and maintainability by a team with deep expertise in that specific stack.
- A Tight Timeframe for a PoC: The project was scoped for a rapid PoC, with an estimated 20-hour budget for the implementation phase. This required a design that prioritized simplicity and speed-to-delivery.
- The Goal of Validation: The primary objective was to validate a classification strategy against a dataset, not to build a production-ready system from day one.
These realistic constraints led to a design that deliberately prioritizes interpretability, tunability and leveraging existing strengths over building a "perfect" solution in a theoretical vacuum.
Assumed Inputs
This design focuses exclusively on the classification engine. It assumes the prior existence of two key inputs:
- A Corpus of Scraped Websites: A local directory containing the raw HTML content of various websites.
- A Labeled Dataset: A simple text file that serves as the "ground truth," mapping each website's domain to a binary label (spam/not-spam).
The design also assumes this initial dataset is well-balanced and representative enough to create a useful set of initial heuristic rules. The document does not cover the implementation of the web scraper or the initial data labeling process.
Defining Success: A Trust-Centric Approach
For a PoC, success is about proving the viability of an approach against clear measurable goals, not just delivering functional code. The core value of this classifier lies in its ability to effectively identify spam while upholding a high standard of trust.
This led to a core tuning philosophy that guided all subsequent metrics and decisions: A False Positive (a legitimate site incorrectly flagged) is significantly more harmful to user trust than a False Negative (a spam site that is missed). Therefore, the entire design is deliberately optimized to ensure the integrity of the results.
Quantitative Goals
To that end, I established a clear set of success criteria:
- Primary Metric (Precision > 90%): Reflecting the core philosophy, the system must be highly precise. At least 90% of the sites it flags as spam must actually be spam.
- Secondary Metric (Recall > 70%): The system must still be effective, correctly identifying at least 70% of all true spam sites in the dataset.
- Health Metric (Accuracy > 80%): The overall accuracy must be significantly better than random chance, serving as a general health check.
Tuning Levers
The design's configuration file would provide two main levers to achieve these metrics:
- Rule Weighting: Individual rule scores would be carefully calibrated. Rules with a higher risk of producing false positives would be given more conservative (lower) scores.
- Threshold Setting: The final classification threshold would be set conservatively high, directly enforcing the "precision-first" principle.
Stretch Goal: Weighted Performance
A more mature success metric, beyond the initial PoC, would be to weight the performance scores by a site's real-world impact. Misclassifying a high-traffic, popular domain is far more damaging than misclassifying an obscure one. A future version of the efficacy test would incorporate a public list like the Tranco Top 1M to give more weight to errors on popular sites, providing a better measure of the classifier's impact on the user experience.
This quantitative and philosophical approach provides a clear framework for evaluating the PoC and tuning its performance.
Core Design Philosophy: Pragmatism Within Constraints
The design is guided by a philosophy of pragmatism, focusing on delivering maximum value and minimizing risk within the defined constraints. When considering the addition of a feature to a legacy system, stability and maintainability are paramount. This led to three core principles:
Interpretability Builds Trust: For a new, critical system like a spam classifier to be adopted by an existing team, its decisions must be explainable. I chose a "white-box" heuristic approach where every classification can be traced back to a specific set of human-readable rules. This is crucial for gaining stakeholder trust and makes the system far easier to debug and maintain than a "black-box" alternative.
Tunability Enables Safe Iteration: A system with hard-coded logic is brittle and risky to modify. My design externalizes all classification rules and their associated weights into a simple YAML configuration file. This decouples the core logic from the code, allowing for safe, incremental tuning and the addition of new rules without requiring a full code deployment and its associated risks.
Leveraging the Existing Ecosystem: The most critical constraint was the mature Perl environment. Instead of fighting this, the design embraces it as a strategic advantage. It leverages Perl's renowned text-processing capabilities, which are exceptionally well-suited for a rule-based engine. Furthermore, it draws architectural inspiration from the proven, time-tested patterns of Apache SpamAssassin, a highly influential and successful open-source project in the domain of heuristic-based filtering. This approach ensures that the proposed solution would be easily understood, built and maintained by an existing Perl-focused engineering team, drastically reducing the project's real-world risk profile.
The Proposed Solution: A Configurable Heuristic Engine
The proposed solution is a modular, self-contained Perl application that functions as a configurable, weighted heuristic engine. This approach directly models the methodology used by successful, time-tested systems like Apache SpamAssassin, which combine a set of distinct rules or "signals" to compute a cumulative spam score. A site is classified as spam if its total score exceeds a predefined threshold.
The application's architecture is designed for simplicity, clarity and testability, with a linear data flow and three decoupled core components.
1. The Feature Extractor (FeatureExtractor.pm)
This is the data collection module. It is responsible for all I/O and parsing, with a single responsibility: to take a path to a scraped website's content and return a simple dictionary (or key-value object) of well-defined features. It has no knowledge of the spam rules themselves.
The initial set of features was inspired by common spamdexing techniques and focuses on signals that are both predictive and computationally inexpensive. They fall into several categories:
- Content-Based: Keyword stuffing density, presence of hidden text (e.g. via CSS) and the text-to-HTML ratio to detect "thin content."
- Link-Based: Total count of outbound links and the ratio of external-to-internal links.
- URL-Based: Lexical analysis of the domain name itself, such as the count of hyphens or numbers.
- Structural: Presence of tags commonly used for deceptive redirects, like
<meta http-equiv="refresh">.
2. The Configurable Rules Engine (RulesEngine.pm)
This is the core logic of the classifier. To provide maximum flexibility and tunability, the rules are not hard-coded. Instead, they are defined in an external, human-readable rules.yaml file. This completely decouples the classification logic from the application code.
A typical rule in the configuration consists of:
- Name: A unique, descriptive identifier (e.g.
EXCESSIVE_OUTBOUND_LINKS). - Feature: The key from the
FeatureExtractorto inspect (e.g.num_outbound_links). - Operator: The comparison to perform (e.g.
GREATER_THAN). - Value: The threshold to compare against (e.g.
200). - Score: The weight (positive or negative) to add to the total spam score if the rule is triggered.
3. The Orchestrator (classify_site.pl)
This is the main command-line script that serves as the application's entry point. It orchestrates the entire process:
- Parses the command-line arguments (e.g. the input file path).
- Loads the classification threshold and all rule definitions from the
rules.yamlfile. - Invokes the
FeatureExtractorwith the input path to get the site's features. - Passes the extracted features and the loaded rules to the
RulesEngineto compute a final spam score and a list of triggered rules. - Compares this score against the threshold to determine the final classification. The orchestrator then produces a final result object containing the classification (spam/not-spam), the total score and the list of specific rules that were triggered, providing full explainability for the decision.
Deep Dive: The Strategic Decision to Defer Machine Learning
The most obvious alternative to a heuristic engine is a Machine Learning (ML) classification model. While an ML approach offers high potential accuracy, I made a deliberate, strategic decision to reject it for the initial PoC phase. This was a pragmatic choice driven by the project's specific constraints: a tight timeframe and the context of a legacy Perl ecosystem.
The key trade-offs I considered were:
1. Expanding on the "Interpretability Builds Trust" Principle
As stated in the core design philosophy, a "white-box" solution is crucial for building trust. The deep dive reveals why this is so critical in practice:
- For Debugging: A heuristic approach is fully traceable. If a site is misclassified, we can see the exact list of rules that were triggered and their scores. This makes identifying and fixing a faulty rule a simple and deterministic process.
- For Stakeholder Buy-in: When demonstrating the PoC to product or business stakeholders, being able to explain precisely why a site was flagged (e.g. "it has an excessive number of outbound links and hidden text") is far more convincing than saying "the model's prediction was 0.92."
- For Team Adoption: For the existing engineering team that would inherit the system, the transparent logic of a heuristic engine dramatically lowers the maintenance burden and empowers them to contribute new rules with confidence.
2. Implementation Feasibility vs. Ecosystem Mismatch
The ~20-hour implementation budget and the Perl technology stack made a full ML workflow infeasible and unwise.
- A responsible ML workflow requires a significant investment in data pipelines, feature scaling, cross-validation, hyperparameter tuning and systematic error analysis. Attempting to rush these steps would produce an untrustworthy model.
- The Perl ecosystem, while powerful for text processing, lacks the mature, world-class ML libraries and tooling of a language like Python. Building a robust ML pipeline in this environment would require significant foundational work, placing it well outside the scope of a rapid PoC.
3. Robustness in a Low-Data Environment
A PoC typically starts with a limited dataset. In this scenario, a complex ML model is at high risk of "overfitting" (learning spurious correlations that do not generalize to new websites). A carefully crafted heuristic system, based on the established first principles of web spam (as documented in sources like Wikipedia and academic research), is often more robust and performs more predictably when data is scarce.
In summary, the decision to defer ML was a conscious, pragmatic trade-off. It prioritized speed-to-learning, interpretability and a low-risk integration path into the existing ecosystem, the most important factors for a successful PoC.
A Multi-Layered Testing Strategy
A classifier is only as good as the confidence we have in its results. Therefore, the design includes a comprehensive, multi-layered testing strategy to ensure correctness, robustness and performance.
Unit Tests (Correctness): These tests would validate the individual components in isolation. For example, we would provide the
FeatureExtractorwith small, self-contained HTML strings to assert that it correctly counts links and calculates ratios. We would provide theRulesEnginewith hardcoded feature dictionaries (key-value objects) to assert that the score calculation is mathematically correct.Integration Tests (Cohesion): These would test the entire application flow, from command-line argument parsing to the final output. By running the main
classify_site.plscript against temporary sample files, we could assert that the components work together as expected.Efficacy / Acceptance Testing (Performance): This is the most critical layer to evaluate the quality of the results. The design includes a dedicated evaluation function that runs the classifier against the entire labeled training dataset. It compares the system's predictions using the ground-truth labels and computes the final Accuracy, Precision and Recall metrics. This provides the quantitative feedback loop essential for tuning.
Adversarial Testing (Robustness): To ensure the system is resilient against real-world, messy data and adversarial attacks, the design includes a strategy for adversarial testing. This would involve a suite of tests that programmatically generate synthetic, challenging test cases:
- Spam Injection: This test would take known "good" sites from the training set and automatically inject spam signals (e.g. adding 100 instances of a keyword in a
<div>withstyle='display:none;'). The test would then assert that the site's spam score increases as expected. - Evasion Testing: This test would take known "spam" sites and attempt to break the classifier. For example, it could programmatically mutate the HTML by removing random closing tags or adding malformed attributes, asserting that the application does not crash and still makes the correct classification.
- Spam Injection: This test would take known "good" sites from the training set and automatically inject spam signals (e.g. adding 100 instances of a keyword in a
The Path to Production: From Prototype to Integrated Service
The PoC is designed as a standalone CLI tool for safe, offline validation. The journey to a robust, production-grade system involves a pragmatic, phased integration into the existing legacy monolith and a strategic evolution of the technology stack.
Phase 1: Asynchronous Integration & Performance Optimization: The first step is to wrap the classifier's logic into an asynchronous worker service. A separate crawling system would be responsible for fetching website content and storing it. The crawler (or another service) would then place a message on a queue containing a pointer to this stored content. The worker would consume these messages, fetch the content, perform the classification and store the result. This is a low-risk integration pattern that prevents the classifier from adding any latency to user-facing requests.
Phase 2: Building a Dynamic Data Pipeline: The static training set would be replaced by a dynamic data pipeline that continuously scrapes and refreshes website data. To allocate resources efficiently, this pipeline would prioritize refreshing popular, high-traffic domains more frequently than less common ones, ensuring the classifier's data is freshest where it matters most.
Phase 3: Strategic Evolution to a Python/ML Service: Once the heuristic engine is proven and a rich dataset has been collected, the next logical step is to introduce Machine Learning. At this point, it becomes a sound architectural decision to build a new, dedicated V2 service in Python to leverage its world-class ML ecosystem (
scikit-learn,pandas, etc.).- This new Python service would initially consume the same features from the
FeatureExtractor, allowing for a direct, apples-to-apples comparison between the heuristic model and the new ML model. - This phased approach allows the organization to strategically introduce a new technology (Python) for a specific, high-value problem, rather than attempting a risky, large-scale rewrite.
- This new Python service would initially consume the same features from the
Production Optimizations
As the system moves to a high-volume production environment, several optimizations would be implemented:
- Early Exit (Short-Circuiting): After the initial rule set is validated, the engine would be modified to stop processing rules as soon as a site's cumulative score exceeds the threshold. During the PoC phase, this is intentionally disabled to ensure we collect data on all triggered rules for better analysis.
- Concurrency Model: The design is inherently efficient, as the classification process is primarily I/O-bound (reading files) rather than CPU-bound (the heuristic checks are computationally cheap). This means a single worker instance could be made more efficient by using an event-driven, non-blocking I/O model to process multiple sites concurrently, maximizing throughput.
Evolving the Product Capabilities
Beyond the technical migration, the architecture allows for significant enhancements over time:
- Richer Heuristics: The modular
FeatureExtractoris designed for extension. While the PoC focuses on simple, static HTML analysis, a production version would be enhanced to extract more sophisticated signals, such as detecting obfuscated text or analyzing the behavior of embedded scripts, to combat more advanced spam techniques. - Automated Rule Tuning: With a dynamic data pipeline in place, we could implement a workflow for automatically tuning the rule weights (or model re-training) based on the latest data, ensuring the classifier continuously adapts to new spammer tactics.
- Reputation History: The system could begin tracking a domain's classification over time. A site that frequently flips between spam/not-spam could incur a reputation penalty, making it harder for adversarial actors to game the system.
- Finer-Grained Classification: While the PoC may operate on a pre-aggregated "site" level, the underlying
FeatureExtractorworks on a page-by-page basis. A major evolution would be to expose this page-level classification to handle large platforms with user-generated content (e.g.github.io). This would allow the system to flag a single malicious page without penalizing the entire legitimate domain.
This evolutionary path, encompassing both the technical stack and the product's capabilities, allows for a gradual, de-risked migration from a simple Perl prototype to a sophisticated, Python-based ML service. It ensures that value is delivered and validated at every stage, prioritizing long-term stability and effectiveness.
Personal & Open Source Projects
netflix-to-srt
View on GitHub →This popular open-source tool (850+ stars) provides a robust, zero-dependency solution for converting Netflix/Youtube/WebVTT subtitle files into the standard .srt (SubRip) format.
- Dual Architecture: Features a Python CLI for backend batch processing and an isomorphic JavaScript implementation for client-side browser conversions.
- High Availability Architecture: Engineered a resilient, decoupled deployment pipeline serving the web interface simultaneously via Cloudflare Pages and GitHub Pages, ensuring near 100% uptime through redundant CDNs.
- Agentic CI/CD: Modernized via AI orchestration to include automated GitHub Actions pipelines and multi-environment unit testing (Python
unittest&node:test) while keeping strict zero-dependency constraints.
Basepaint Pipeline
View on GitHub →An open-source archival pipeline for the generative art community basepaint.xyz. Architected an asynchronous Python orchestrator (asyncio, tenacity) using pydantic schemas to enforce deterministic, structured LLM outputs from rate-limited vision models, generating automated, high-quality PDF metadata archives.
Tinymem
A hardware-constrained memory game for the Thumby microcontroller, serving as the technical foundation for my PyDayBCN 2023 presentation. Written in under 50 lines of MicroPython, it demonstrates extreme resource-constrained development across audio, sprite rendering and I/O.
View on GitHub →Rhythm Radar (2016)
An experimental real-time rhythm visualizer built with D3.js. This proof-of-concept uses polar coordinates to create an intuitive "radar" display for drum patterns, offering a novel alternative to traditional linear notation. The project was inspired by a desire to to understand complex rhythms in real time, especially when multiple instruments and loops are involved.
View on GitHub →This Homepage
A custom-built, zero-framework static site generator powered by Node.js.
- Architecture: Employs a headless Markdown approach with parallelized build tasks and per-page CSS loading for an exceptionally fast render path.
- Discipline: Enforces strict Conventional Commits for an automated changelog and maintains WCAG-compliant accessibility and performance standards.
Pycrastinate (2014)
A language-agnostic tool for managing TODO and FIXME comments across entire codebases, presented in full at PyCon Sweden 2014 and abridged at EuroPython 2014.
- Architecture: Built as a configurable pipeline, the tool finds tagged comments, enriches them with
git blamemetadata (author, date) and generates reports. - Purpose: This early project was an exploration into building developer tooling and demonstrates an early interest in code quality and maintainability.
Presentations
PyCon Sweden 2019: Practical Optimizations
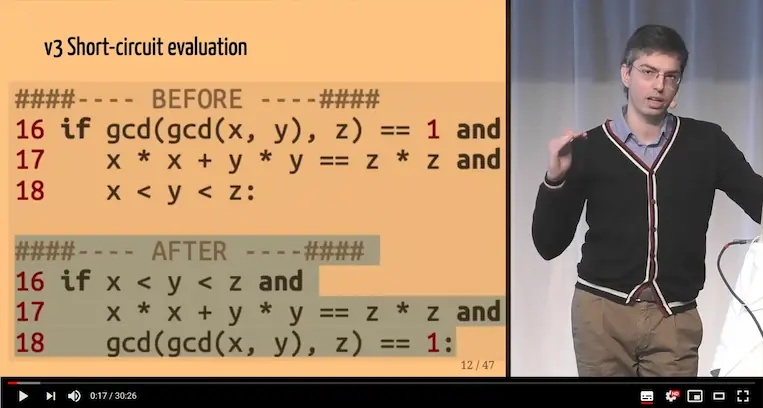
This talk demonstrates solutions to bottlenecks, transitioning from O(n³) to O(1) through memoization, search-space reduction, profiling... The analysis goes as deep as CPython bytecode and showcases 10+ incremental production-ready techniques.
Education & Interests
M.Sc. from NTNU/UPC, fluent in English and active in community leadership.
See more
M.Sc. in Informatics Engineering (EQF 7), Highest Honours
Norwegian University of Science and Technology (NTNU) & Universitat Politècnica de Catalunya (UPC - BarcelonaTech), 2011
- Completed a 5-year, 300+ ECTS program in Informatics Engineering at UPC, with specializations in Data Management and Software Engineering.
- Authored a Master's Thesis on Test-Driven Conceptual Modelling at NTNU as part of the ERASMUS programme. This received the highest possible grade (A with Highest Honours) from both institutions.
Languages
- Native: Catalan, Spanish
- Full Proficiency: English (10+ years professional experience; Cambridge CPE/C2)
- Conversational: Swedish (6 years residency; A2 certified)
- Basic: Norwegian (EILC Bokmål course)
Leadership & Interests
- Community Leadership (VP & Treasurer, 2006-2010): Co-managed a non-profit cultural association aimed at providing positive leisure alternatives for local youth. Oversaw budgets, secured public funding and organized community events, including annual LAN parties and boardgame weekends.
- Personal Interests: I enjoy classical music, performing on piano, harpsichord and participating in organ masterclasses. I'm also an avid reader and fond of indie games, currently in the reviewing stage to publish a game in PlayDate's Catalog and previously developing PoCs for Thumby like a Simon clone and a multiplayer Pong clone.
Credentials
Degrees, diplomas and language certificates are available for review on GitHub.